由禧云國際聯合中國烹飪協會、億歐智庫共同撰寫的《2018年中國團餐行業研究報告》正式發布。報告聚焦中國團餐市場的現狀、挑戰與未來趨勢,并重點剖析了以云計算、大數據為支撐的業務外包服務,如何為這一傳統行業注入新的發展動能。
報告指出,中國團餐市場規模龐大且持續增長,已成為餐飲行業的重要支柱。傳統團餐運營模式長期面臨成本控制難、食品安全管控壓力大、運營效率低下、消費者需求日益多樣化等多重挑戰。在此背景下,數字化轉型與專業化服務外包成為行業尋求突破的關鍵路徑。
基于云的業務外包服務:重塑團餐價值鏈
報告的核心洞察之一,是深入闡述了“基于云的業務外包服務”對團餐行業的變革性影響。這類服務并非簡單的勞務或環節外包,而是依托云計算平臺,將食材供應鏈管理、食品安全追溯、智能收銀與支付、會員營銷、數據分析、人才培訓等核心業務模塊進行標準化、線上化整合,為團餐企業提供一站式、可配置的數字化解決方案。
- 提升效率與透明度:通過云平臺,團餐企業可以實現從采購、倉儲、加工到售賣的全流程數字化管理,大幅減少人為誤差和信息滯后,實現降本增效。供應鏈的透明化也有助于強化食品安全管控。
- 數據驅動智能決策:云平臺匯集了消費數據、運營數據、供應鏈數據等。通過大數據分析,團餐管理者可以精準把握消費趨勢、優化菜單結構、預測食材需求,實現從經驗驅動向數據驅動的科學決策轉變。
- 賦能精細化運營與創新:基于云的會員系統和營銷工具,幫助團餐企業建立與消費者的直接連接,開展個性化營銷,提升客戶粘性與滿意度。靈活的服務模塊組合,也使企業能更專注于核心業務與模式創新。
- 降低數字化轉型門檻:對于大量中小型團餐企業而言,自建IT系統成本高昂、技術復雜。基于云的外包服務采用SaaS(軟件即服務)模式,以相對低的成本和更快的部署速度,為其提供了普惠的數字化升級通道。
行業展望:生態化協同與品質化升級
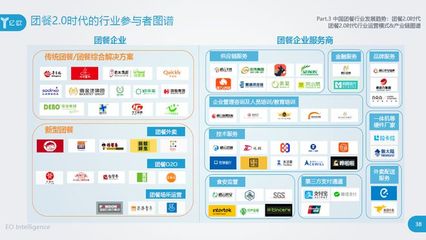
報告最后展望,未來團餐行業的競爭將不再是單個企業的競爭,而是供應鏈、數據鏈、服務鏈整合能力的競爭。以禧云國際等為代表的產業路由器,通過構建基于云的開放服務平臺,正在連接上游供應商、中游團餐運營企業與下游消費者,推動整個團餐產業向標準化、集約化、智能化的生態共同體演進。
隨著消費升級,團餐市場對營養、口味、體驗的要求不斷提高。基于云的業務外包服務,通過賦能企業提升運營效率和創新能力,最終將助力整個行業實現從“吃飽”到“吃好”的品質化升級,開拓更廣闊的市場空間。
《2018年中國團餐行業研究報告》的發布,不僅為行業提供了詳實的現狀圖譜,更指明了以云計算賦能業務外包這一清晰的發展路徑,對團餐企業、投資者及相關從業者具有重要的參考價值。