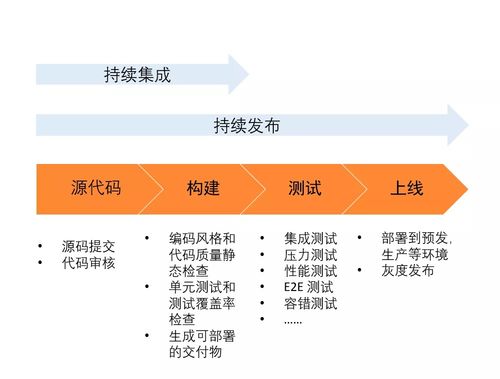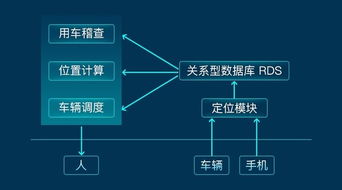
在數(shù)字化轉(zhuǎn)型浪潮席卷全球的今天,企業(yè)對(duì)于高效、安全、靈活的IT基礎(chǔ)設(shè)施與數(shù)據(jù)管理服務(wù)的需求日益迫切。為此,華為云數(shù)據(jù)庫近日正式推出了一系列針對(duì)性的行業(yè)解決方案,尤其聚焦于支撐和優(yōu)化基于云計(jì)算模式的業(yè)務(wù)外包服務(wù),為企業(yè)客戶提供了從數(shù)據(jù)存儲(chǔ)、處理到智能分析的一站式云端數(shù)據(jù)能力引擎,助力其外包業(yè)務(wù)實(shí)現(xiàn)降本增效與敏捷創(chuàng)新。
一、 洞察行業(yè)痛點(diǎn),精準(zhǔn)推出解決方案
業(yè)務(wù)外包服務(wù),作為企業(yè)整合外部專業(yè)資源、聚焦核心競爭力的重要手段,其成功高度依賴于可靠、彈性且成本可控的IT后臺(tái)支撐。傳統(tǒng)自建數(shù)據(jù)中心模式常面臨初期投入大、運(yùn)維復(fù)雜、擴(kuò)展性差等挑戰(zhàn),難以匹配外包業(yè)務(wù)快速變化、季節(jié)性波動(dòng)或項(xiàng)目制啟動(dòng)的需求。華為云數(shù)據(jù)庫深刻洞察到這一行業(yè)共性痛點(diǎn),推出的解決方案旨在將數(shù)據(jù)庫能力以云服務(wù)的形式輸出,使外包服務(wù)提供商及其客戶能夠像使用水、電一樣便捷地獲取高性能、高可用的數(shù)據(jù)庫服務(wù),無需操心底層硬件與基礎(chǔ)軟件的購置、部署和維護(hù)。
二、 方案核心優(yōu)勢(shì):云原生、全場(chǎng)景、高安全
- 云原生架構(gòu),極致彈性與敏捷:華為云數(shù)據(jù)庫解決方案基于云原生技術(shù)構(gòu)建,具備秒級(jí)擴(kuò)容縮容能力。外包服務(wù)商可根據(jù)項(xiàng)目需求動(dòng)態(tài)調(diào)整數(shù)據(jù)庫資源,在業(yè)務(wù)高峰時(shí)快速提升性能以保障服務(wù)體驗(yàn),在低谷時(shí)自動(dòng)釋放資源以優(yōu)化成本,實(shí)現(xiàn)真正的按需使用、按量付費(fèi)。這特別適用于人力資源外包、客服外包、財(cái)務(wù)流程外包等具有明顯波峰波谷特征的業(yè)務(wù)場(chǎng)景。
- 全場(chǎng)景數(shù)據(jù)服務(wù)覆蓋:方案涵蓋了關(guān)系型數(shù)據(jù)庫(如GaussDB)、非關(guān)系型數(shù)據(jù)庫、數(shù)據(jù)倉庫、數(shù)據(jù)遷移工具等全套產(chǎn)品與服務(wù)。無論是需要強(qiáng)一致事務(wù)支持的訂單處理系統(tǒng)(OLTP),還是進(jìn)行海量數(shù)據(jù)分析的報(bào)表與決策支持系統(tǒng)(OLAP),亦或是處理半結(jié)構(gòu)化日志、文檔的應(yīng)用程序,華為云都能提供對(duì)應(yīng)的數(shù)據(jù)庫引擎,滿足業(yè)務(wù)外包中多樣化的數(shù)據(jù)存取與計(jì)算需求。
- 企業(yè)級(jí)安全與合規(guī)保障:數(shù)據(jù)安全是業(yè)務(wù)外包的生命線。華為云數(shù)據(jù)庫解決方案內(nèi)置了從網(wǎng)絡(luò)隔離、數(shù)據(jù)加密(靜態(tài)與傳輸中)、訪問控制到完整審計(jì)追蹤的多層安全防護(hù)體系。積極遵循全球多地(如中國、歐洲等)的嚴(yán)格數(shù)據(jù)隱私與安全合規(guī)標(biāo)準(zhǔn)(如GDPR、等保2.0等),為處理敏感信息(如個(gè)人身份信息、財(cái)務(wù)數(shù)據(jù))的外包服務(wù)提供合規(guī)性基石,解除企業(yè)與最終客戶的后顧之憂。
三、 賦能業(yè)務(wù)外包服務(wù)的具體價(jià)值
- 降低成本,提升競爭力:外包服務(wù)商無需巨額前期資本支出建設(shè)數(shù)據(jù)中心,轉(zhuǎn)向運(yùn)營支出(OpEx)模式,大幅降低入門門檻和運(yùn)營成本,從而能夠?yàn)榭蛻籼峁└邇r(jià)格競爭力的服務(wù)方案。
- 加速服務(wù)部署與迭代:云數(shù)據(jù)庫的即開即用特性,使得新外包項(xiàng)目的IT后臺(tái)準(zhǔn)備時(shí)間從數(shù)周縮短至幾分鐘,極大地加快了服務(wù)上線速度。敏捷的開發(fā)和測(cè)試環(huán)境搭建也支持服務(wù)功能的快速迭代與創(chuàng)新。
- 增強(qiáng)業(yè)務(wù)連續(xù)性與可靠性:華為云在全球布局了多個(gè)可用區(qū),其數(shù)據(jù)庫服務(wù)提供高可用(HA)架構(gòu)、跨區(qū)域容災(zāi)備份能力,確保外包業(yè)務(wù)系統(tǒng)能夠達(dá)到99.95%以上的可用性承諾,最大程度減少服務(wù)中斷風(fēng)險(xiǎn)。
- 釋放數(shù)據(jù)潛能,驅(qū)動(dòng)智能升級(jí):結(jié)合華為云在人工智能與大數(shù)據(jù)分析領(lǐng)域的能力,該解決方案能幫助外包服務(wù)商深入挖掘業(yè)務(wù)數(shù)據(jù)價(jià)值,實(shí)現(xiàn)從“流程執(zhí)行”到“洞察驅(qū)動(dòng)”的轉(zhuǎn)變。例如,在客服外包中通過數(shù)據(jù)分析優(yōu)化排班與話術(shù);在IT外包中通過智能運(yùn)維預(yù)測(cè)潛在故障。
四、 展望未來
華為云數(shù)據(jù)庫行業(yè)解決方案的推出,標(biāo)志著云數(shù)據(jù)庫服務(wù)正從通用型基礎(chǔ)設(shè)施向深入行業(yè)場(chǎng)景、賦能具體業(yè)務(wù)模式的方向深化。對(duì)于基于云的業(yè)務(wù)外包服務(wù)產(chǎn)業(yè)而言,這不僅僅是一次技術(shù)工具的升級(jí),更是其商業(yè)模式向更輕資產(chǎn)、更敏捷、更智能方向演進(jìn)的重要助推器。隨著企業(yè)數(shù)字化轉(zhuǎn)型的持續(xù)深入,華為云有望通過其不斷完善的數(shù)據(jù)庫及整體云服務(wù)生態(tài),與廣大外包服務(wù)商及企業(yè)客戶攜手,共同開拓?cái)?shù)字化外包服務(wù)的新藍(lán)海,創(chuàng)造更大的商業(yè)與社會(huì)價(jià)值。